Migrate Data Lakehouse từ BigQuery sang Apache Doris tiết kiệm $4,500 mỗi tháng
Mô tả overview việc migrate Data Platform từ BigQuery sang Apache Doris, bài viết không đi sâu vào kỹ thuật mà chỉ nhầm giới thiệu 1 Data Lakehouse mới — Apache Doris.
I. Bài toán đặt ra
Để cắt giảm chi phí BigQuery, sếp cũ mình làm ở 1 công ty retail (mình không tiện tiết lộ tên) nhờ mình với vai trò là Advisor để research thiết kế Data Platform trên On-Premise. Do công ty này apply Data-Driven nên chi phí cho việc dùng data khá lớn mỗi tháng công ty chi khoảng $6,000 cho BigQuery (thời điểm hiện tại có giá scan mỗi TB là 8.44$ — Pay as you go chưa bao gồm thuế và chi phí lưu trữ).
Mình summarize chi phí BigQuery do các luồng sau:
- ETL: Hơn 500 tables từ hệ CRM, hệ thống OMS, các tracking trên web/app, Affiliate, Marketplace, từ social media… (chỉ store những tables cần cho nhu cầu, tables không cần thì chỉ lưu file parquet ở GCS khi cần thì load lên).
- Các phòng ban build gần 120 tables Data Marts: phòng kế toán, phòng marketing, phòng sales, phòng vận hành, các báo cáo cho BOD,…
- Có 45 Dashboards, trung bình mỗi Dashboard có khoảng 7–10 Charts.
- Các hệ thống chạy Campaigns tương tác trên BigQuery vì cần query qua lượng lớn dữ liệu (code bằng Java, đọc dữ liệu từ BigQuery).
Bài toán khá phức tạp, sau khi xem qua việc dùng dữ liệu thì mình nhận thấy Data Lakehouse cũ đã optimize việc sử dụng BigQuery rồi, họ đã áp dụng tốt những technique mà Google suggest: Partition, Clustering, Materialized Views, Denormalized, Cached,… Ngoài ra họ còn có những con worker đọc audit logs để detect những query tốn kém và alert để đảm bảo các query đều theo rules trong tầm kiểm soát. Nên ở phía BigQuery gần như không thể optimize thêm nữa. Do đó sử dụng hệ On-Premise từ các Open sources là lựa chọn lúc này, tuy nhiên nó sẽ trade off với chi phí vận hành, chắc các bạn dùng Cloud và migrate xuống On-Premise sẽ hiểu được nổi khổ này.
II. Tiếp cận vấn đề
Bài toán đặt ra của quá trình migration này là cần đáp ứng:
- Tận dụng luồng ETL cũ để ít thay đổi nhất có thể.
- Tận dụng lại các Data Marts mà các team đã build, 90% họ build bằng SQL nên hệ Lakehouse mới cần support SQL mạnh mẽ thì có thể tận dụng được luồng cũ.
- Cần đảm bảo các services hiện tại (viết bằng Java) có thể kết nối đến Lakehouse, ít thay đổi logic code nhất có thể.
- Build lại các Dashboards trên Metabase (BI tool), phần này hơi vất vả vì có nhiều Window Functions của Doris và BigQuery khác cú pháp nhau, hoặc 1 số function khác tên, hoặc không hỗ trợ…
- Performance hệ thống tốt, ổn định, linh hoạt và có thể dễ dàng mở rộng.
- Kì vọng có thể đọc được dữ liệu từ Apache Iceberg (phần này do team Machine Learning xử lý các models xong export kết quả).
- Kì vọng lưu được dữ liệu dạng vector cho AI Chatbot.
- Các team sử dụng có thể học cách dùng Data Lakehouse mới không quá khó khăn, nhất là cú pháp SQL cần tương tự.
- Build xong thì cần ít chi phí bảo trì system, hoặc tốn thời gian bảo trì ban đầu để hiểu cách vận hành sau đó thì chi phí bảo trì không quá nhiều.
Với các bài toán trên mình thì mình thấy open source Apache Doris (link https://doris.apache.org/ ) là phù hợp (do 1 bạn người Trung Quốc giới thiệu mình trước đó, khi thực hiện migrate này thì mình đã có 5 tháng kinh nghiệm làm việc với Doris).
Với lượng dữ liệu và nhu cầu hiện tại khoảng 20TB data scanning mỗi ngày (tính theo chart của BigQuery, giờ cao điểm ở các khung giờ 00:00–06:00, 8:30–11:00 và 14:30–16:00), mình dùng cấu hình phần cứng như sau:
- 3 Nodes Followers, mỗi node: 20GB RAM, 12 CPU, SSD 200 GB;
- 1 Node Observer: 8GB RAM, 8CPU, SSD 100GB;
- 3 Nodes Backends, mỗi node: 64GB RAM, 32 CPU, SSD 3TB;

Với cấu hình đó thì chi phí mỗi tháng khoảng 37 triệu VND (dùng dịch vụ server do 1 công ty VN cung cấp, mỗi nhà cung cấp có giá khác nhau, mình không biết là giá này đã bao gồm giảm giá 25% chưa).
Lý do chọn Apache Doris:
- Dự án đang được công ty Baidu ở Trung Quốc phát triển cho nhu cầu công ty họ, đây là 1 BigTech ở TQ và được nhiều công ty khác sử dụng: Alibaba, Tencent, Xiaomi… và gần đây nhiều công ty công nghệ ở Ấn Độ dùng.
- Cộng đồng sử dụng chưa nhiều so với Clickhouse, tuy nhiên họ có group support trên Slack, khi gặp vấn đề có thể hỏi trực tiếp vào group và sẽ có câu trả lời từ nhà phát triển (đôi khi có những người từng gặp lỗi đó họ sẽ trả lời).
- Dùng MySQL Protocol làm cổng kết nối, nghĩa là các ứng dụng/tools kết nối được MySQL thì kết nối được Doris.
- Về High Availability: Khi 1 node bị down, ta vẫn có thể query được dữ liệu, miễn là khi tạo table cần đều chỉnh thông số replica của table đó.
- Về Scalability: Có thể mở rộng theo chiều rộng hoặc chiều ngang tuỳ nhu cầu, trong trường hợp Disk không còn space thì có thể lưu dữ liệu ở HDFS, S3, GCS,… để dùng Federated Query để retrieve dữ liệu.
- Về Performance: Doris áp dụng cơ chế Massive Parallel Processing, Predicate Pushdown, Partition, nhiều cơ chế Indexing, Rollup (tính năng này rất hữu ích)… nên performance khá ổn. Lưu dạng columnar format, có các cơ chế join (tự tạo các cơ chế broadcast, hoặc tận dùng replica để dùng local join tránh shuffle), upsert dữ liệu flexible hơn Clickhouse.
- … còn nhiều lý do nữa, trên đây mình chỉ nêu 1 phần.
III. Giải quyết vấn đề
1/ Migrate luồng ETL từ Data Sources
Dưới đây là kiến trúc dữ liệu ở mức high level của luồng dữ liệu trước khi migrate:
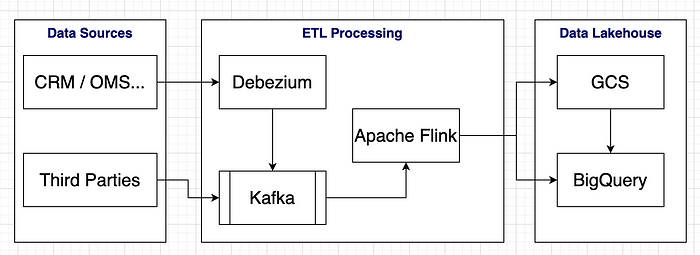
Công ty cũng đã tiết kiệm chi phí nên dùng open sources cho phần ETL Processing, chỉ dùng GCS và BigQuery thôi. Mình sẽ không đào sâu phần Architecture này ở đây. Phần này mình chỉ show đơn giản cho dễ hình dung việc migration, nếu đầy đủ thì có Apache Iceberg, Trino… cho các team xử lý adhoc, A/B Testing,…
Còn đây là kiến trúc sau khi migrate:
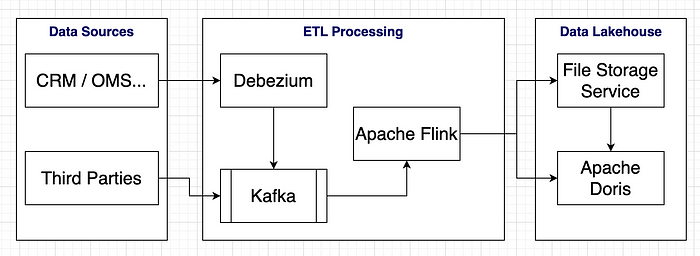
Để bớt effort thì tụi mình đã dùng kiến trúc tương tự, Apache Doris có hỗ trợ Connector cho phép Apache Flink upsert trực tiếp vào.
File Storage Service là 1 service mà công ty cung cấp server họ cung cấp, họ gọi là S3 (dùng client connect tương tự như S3, mình đoán core bên dưới có thể là MinIO).
Apache Doris có hỗ trợ đọc realtime dữ liệu trực tiếp từ Kafka và thực hiện ETL đơn giản, nhưng để giảm burden cho Doris và tận dụng lại các xử lý từ Apache Flink nên mình chỉ tạo thêm abstract đẩy dữ liệu vào Doris, khá đơn giản.
Đây là kiến trúc để chạy dữ liệu mới. Việc migrate phần dữ liệu cũ vất vả hơn, mình thực hiện tuần tự các bước:
- B1: Script đọc schema theo từng table trên BigQuery, sau đó tạo tương ứng table với schema và partition column tương tự (may là không dùng datatype phức tạp) trên Doris. Thời điểm hiện tại Doris chưa support clustering columns bù vào đó nó có hỗ trợ các loại index tuỳ vào công dụng: Bitmap Index, Prefix Index, Bloom Filter Index, Inverted Index…
- B2: Script export từng table trên BigQuery ra parquet file và lưu ở GCS
- B3: Script đọc file trực tiếp từ GCS lên Doris (Doris support việc đọc dữ liệu từ các File Storage System khá đơn giản, chỉ cần 1 câu SQL).
Thời điểm migrate tụi mình có chuẩn bị sẵn kịch bản và 1 số technique để đảm bảo khi luồng ETL mới trên Doris khi consume dữ liệu mới thì dữ liệu consistency giữa BigQuery và Doris.
2/ Migrate luồng Data Marts
Phần này khá vì luồng cũ dùng Apache Airflow, họ định nghĩa các SQL (dễ quản lý SQL version khi build Data Marts) sau đó dùng Google Cloud BigQuery Operator để tương tác với BigQuery, phần này mình sửa BigQuery Operator sang MySQL Operator để connect vào Doris. Phần SQL Doris tương thích với luồng cũ đến 90% nên tận dụng các SQL statement cũ được.
3/ Migrate các services đang trỏ vào BigQuery
Phần này cũng may mắn là các services đa phần dùng các custom SQL đơn giản, và các tables mà họ dùng đa phần được tính toán sẵn (Denormalized, các Big-Tables hoặc các Materialized Views) nên gần như không thay đổi, chỉ thay đổi phần connection đến Doris chứ không thay đổi logic code.
4/ Migrate phần Dashboards ở Metabase
Metabase khi kết nối đến Doris thì sẽ có 1 số Dashboards bị lỗi vì cú pháp hàm khác nhau, ví dụ ở Doris dùng Window Functions hàm LEAD thì LEAD(expr, offset, default) OVER (partition_by_clause order_by_clause) trong khi ở BigQuery thì: LEAD(expr) OVER (partition_by_clause order_by_clause)… và nhiều lỗi vặt tương tự, có lỗi logic khi thực hiện cần bỏ cả charts đó để build lại cú pháp mới trên Doris.
5/ Monitoring
Sau khi migrate xong phần nào, tụi mình dùng Airflow để kiểm tra số liệu của BigQuery và Doris từng table, và từng chart, khi table nào lệch số thì sẽ zoom vào để xử lý, nhìn chung chưa thấy lỗi nào phức tạp, số lượng xảy ra lệch chưa đến 5%.
IV. Đánh giá
Sau khi luồng ETL tự động chạy ổn định và số liệu monitor ổn định được 1 tuần thì các team đã được phiên bản dùng thử, sau dùng thử được 4 tuần thì hiệu năng vẫn ổn, đôi khi bị chết 1 con FE (nhưng vẫn query được hệ thống, chết backend mới ảnh hưởng hiệu năng vì lúc đó không tận dụng hết parallel các con server, khi chết tầm 2s là nó tự sống lại), những giờ cao điểm thường query chậm do job ETL chiếm hơn 70% resource -> config lại resource cho account ETL không chiếm quá 40% resource là giải quyết được vấn đề (Doris cung cấp cơ chế share resource giữa các group_account - mỗi group chứa nhiều accounts, bình thường resource đang free thì có thể dùng vượt quá phần được cấp, đến khi các group_account dùng nhiều tranh nhau resource thì mỗi group chỉ được dùng tối đa phần được cấp, trường hợp này account ETL chỉ dùng tối đa 40% trong giờ cao điểm nhiều người dùng cùng lúc).
Team sẽ cho 2 hệ thống chạy song song 2–3 tuần nữa, nếu ok hết thì sẽ tắt luồng ở BigQuery.
Hiện chưa tối ưu lắm, cũng chưa dùng hết các tính năng mà Apache Doris cung cấp, nếu có thời gian khai thác để dùng có vẻ giải quyết được nhiều bài toán lắm.
Team có 1 DE, 1 Software Engineer, 1 DA thực hiện trong 4 tuần.
Ưu điểm khi chuyển sang hệ thống mới:
- Dễ thấy nhất là tiết kiệm chi phí, giảm từ $6,000 xuống còn $1,500 mỗi tháng
- Import dữ liệu trực tiếp từ Apache Iceberg — kết quả của team ML và Mining dữ liệu mà không cần tạo pipeline để đẩy như ở BigQuery.
- Hỗ trợ lưu dữ liệu dạng vector cho AI Chatbot, không cần tạo pipeline đẩy vào Redis như trước, mà chỉ import trực tiếp từ File Store Service (S3) được team ML export.
- Cơ chế Rollup giúp đọc các dữ liệu aggregation của các tables 1 cách hiệu quả.
- Hot storage và cold storage trong cùng 1 table, những dữ liệu cũ quá ít dùng có thể lưu nó xuống cold storage (trên File Store Service), khi cần dữ liệu cold thì Doris có cơ chế tự xử lý để tạo kết quả cho người dùng (hơi chậm tí vì nó dùng cơ chế lấy từ cold storage).
Nhược điểm:
- Khó bảo trì, khi cần phải tốn nhiều thời gian điều chỉnh các config để hệ thống hoạt động như mong đợi (có hơn 100 params configuration).
- Người dùng sẽ gặp lỗi out of memory nếu quá nhiều users dùng tại 1 thời điểm vượt quá giới hạn RAM hiện tại (trường hợp này là các query tranh giành resource RAM nên có người gặp lỗi có người không gặp lỗi tuỳ process và group_account chứ không phải toàn bộ bị).
- Đôi khi việc replica dữ liệu giữa các node bị mất đồng bộ do network hoặc 1 nguyên nhân nào đó mà cơ chế replica retries tự động thực hiện không thành công, lúc này cần thiết lập cơ chế xử lý tự động bằng worker bên ngoài (Doris quản lý 1 đơn vị lưu trữ gọi là Tablet, metadata các node sẽ ghi nhận việc ETL dữ liệu vào 1 table cụ thể sau đó cập nhật version trong metadata, Doris cung cấp cách xử lý khi mất đồng bộ bằng 1 câu SQL).
- Đôi khi version mới có bugs, nên version mới lên thì xem cộng đồng có report bugs không trước khi quyết định upgrade.
- Chưa hỗ trợ tốt việc xử lý text trên Tiếng Việt, tính năng full-text search trên Tiếng Việt dùng không tốt.
- Server mà bên mình dùng là do 1 công ty ở VN cung cấp, có vẻ họ dùng OpenStack nên đôi lúc không ổn định, lâu lâu có mất kết nối 1 node phải nhờ bên họ xử lý, tuy nhiên do tính High Availability nên trường hợp này vẫn dùng được Doris, chỉ là performance sẽ giảm đi so với bình thường (việc mất kết nối này không xảy ra thường xuyên, vài tháng mới bị 1 lần). Những lần như vậy nếu mất connect ở con Backend thì cần rebalance lại dữ liệu nếu thời điểm đó có ETL job đang hoạt động.
Bài học cho quá trình migrate này:
- Chưa tính toán bandwidth kỹ nên đôi khi Doris đọc dữ liệu table cũ từ GCS đôi lúc bị exceed.
- Team migrate không process full-time, việc migrate này bỏ công sức 70% thời gian thực hiện và 30% handle việc khác, bị interrupt bởi việc khác nên performance không như mong đợi (mình thì làm part-time).
- Đối với các luồng realtime, các file storage ghi vào có size rất nhỏ, cần điều chỉnh config compaction để Doris có cơ chế merge file theo group, vậy sẽ cho performance query tốt hơn.
- Tốn khá nhiều thời gian cho việc kiểm tra các tables ở Data Marts filter theo cột nào để chọn loại index cho phù hợp, thay vì có 1 tool quản lý metadata như Datahub thì chỉ cần scan vào và tạo tự động.
- Việc kiểm tra chất lượng dữ liệu chưa được chặt chẽ, cần kết hợp count và sum các metrics, count từng dimension theo metrics để đảm bảo chính xác cao.
- Hệ thống cũ được sếp mình xây dựng mang tính dễ mở rộng, dễ tích hợp và dễ migrate, nên hầu như không đổi luồng hay đổi logic nhiều, tận dụng tối đa hệ thống cũ, điểm này rất đáng để mình học hỏi.
Bài viết này chưa đi chuyên sâu vào kỹ thuật về các technique của Data Lakehouse mới, việc chọn công nghệ nó cũng là 1 quá trình mà mình cũng chưa nói kỹ phần này.
Nay Data Lakehouse các team đã sử dụng ổn định 4 tuần, cả CTO và CFO đều happy. Tuy nhiên cần dùng nhiều hơn nữa mới có thể đánh giá được khách quan hơn.
Lưu ý: Dùng BigQuery vẫn sướng hơn Doris, vì Doris là open source nên có lỗi vặt, khi dùng đòi hỏi phải apply nhiều technique phức tạp hơn BigQuery để đảm bảo cluster ổn định, hoặc phải tốn effort để maintain cluster, nhưng nếu dùng lâu và hiểu cách vận hành thì chi phí maintain không nhiều. Tuy nhiên mình vẫn thích dùng BigQuery hơn :D.
Tài liệu tham khảo:
- Debezium: https://debezium.io/
- Apache Doris: https://doris.apache.org/
- Tencent blog: https://medium.com/geekculture/tencent-data-engineer-why-we-go-from-clickhouse-to-apache-doris-db120f324290
Các bạn có góp ý gì thì hãy để lại bình luận để chúng ta cùng học hỏi nhé!
